Unlock Unstructured Data with Intelligent Document Processing (IDP)
Leverage ProcessMaker IDP and advanced OCR capabilities to turn unstructured data into actionable insights
- Replace manual data entry with automated AI-driven data extraction and classification to reduce errors and ensure data integrity.
- Turn unstructured and semi-structured data from invoices, contracts, emails, PDFs, pictures, etc. into actionable insights.
- Initiate automated workflows to manage exception handling, keeping your skilled workforce focused on high-value activities.
- Replace manual data entry with automated AI-driven data extraction and classification to reduce errors and ensure data integrity.
- Turn unstructured and semi-structured data from invoices, contracts, emails, PDFs, pictures, etc. into actionable insights.
- Initiate automated workflows to manage exception handling, keeping your skilled workforce focused on high-value activities.
Trusted by 3 Million Users Worldwide
>80%
of business data is unstructured
>80%
of manual data entry can be automated
≥99%
accuracy with Intelligent OCR & advanced machine learning
>1 Billion
documents processed by ProcessMaker IDP to date
ProcessMaker IDP critical capabilities

Intelligent Document
Processing (IDP)
Unlock insights from unstructured data with intelligent OCR for data extraction & classification

Document
Management System
Combined with enterprise-grade DMS to securely store and retrieve processed data

Intelligent Process
Automation
Turn collected data into insights that trigger automated workflows via AI-driven decision engine

AI-Powered Natural
Language Search
Retrieve any content virtually instantaneously from your processed document.
ProcessMaker IDP Features
Intelligent Document Processing (IDP) is a powerful software solution that utilizes AI technologies to capture, transform, and process data from various types of documents. It offers numerous benefits for businesses, enhancing efficiency, reducing costs, and enabling faster knowledge sharing.
Intelligent OCR & Computer Vision

ProcessMaker's Intelligent OCR doesn't just scan; it understands. With state-of-the-art technology, it guarantees up to 99% accuracy, ensuring that vital details from documents like contracts, tax IDs, and invoice amounts are accurately captured.
Extensive Document Handling

Over a billion documents, from semi-structured to completely unstructured formats like images, emails, and PDFs, have been seamlessly processed. This robustness ensures every piece of critical information is unlocked and put to use.
Deep Learning Capabilities

Beyond just scanning, the deep learning capabilities ensure that even complex documents like handwritten forms are interpreted accurately. This technology feeds essential data points directly into the systems, making them readily available for decision-making.
NLP & Data Enrichment
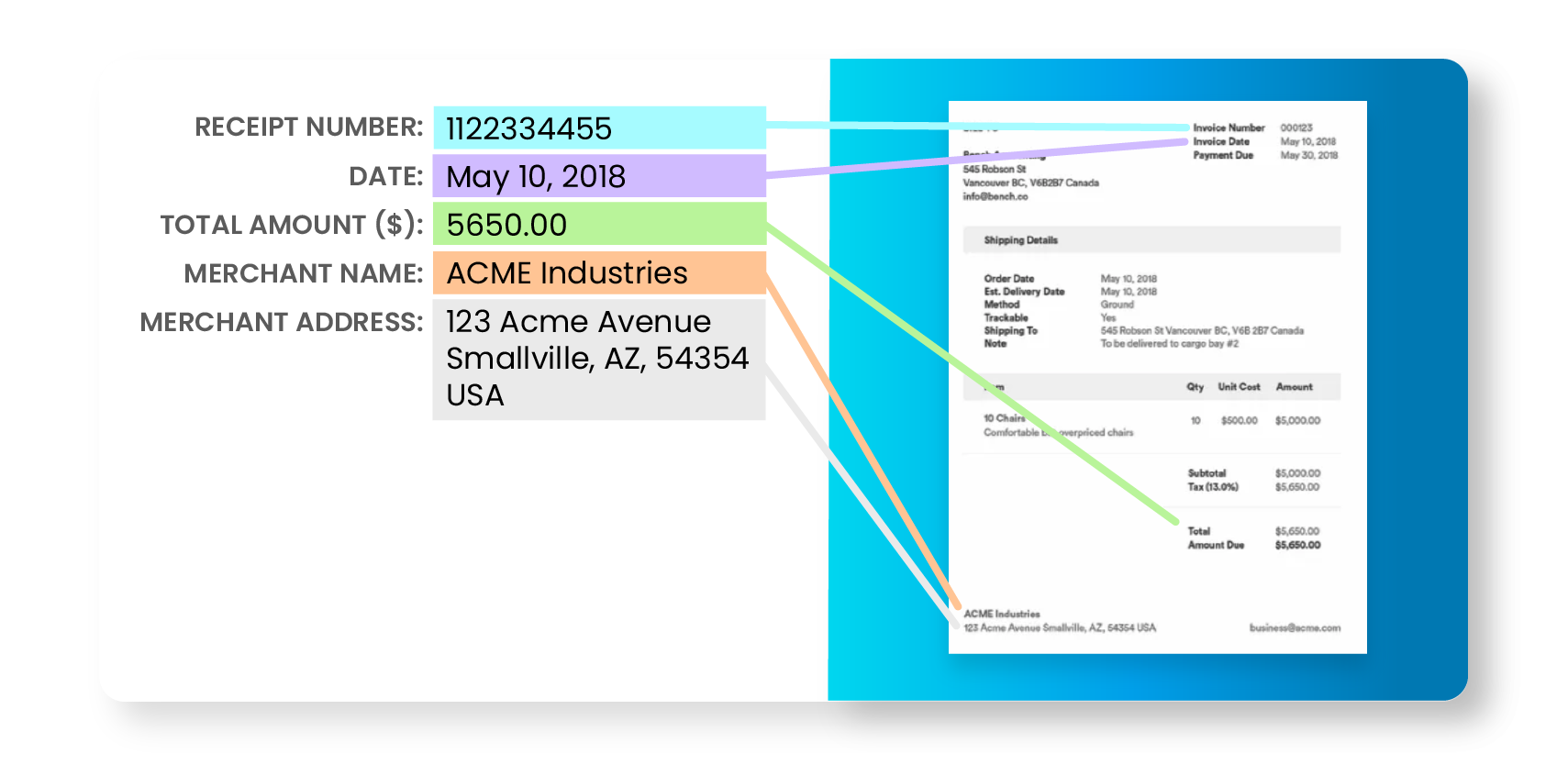
Natural Language Processing technology ensures data is extracted, understood, and enriched. This facilitates advanced functionalities like instant document search, typo corrections, and intelligent data analytics.
Decision Engine
Embrace simplicity in handling complex decisions with ProcessMaker. Our platform offers a flexible approach that manages multiple decision options outside the process flow, eliminating the need for scripting. Use our intuitive decision tables to easily view, understand, and represent business rules in your processes. Simplify decision-making, increase transparency, and optimize outcomes with ProcessMaker’s streamlined tools.

Go beyond basic workflow automation with intelligent automation
Unlock Hyper-Productivity™
Enable end-to-end process automation with a platform giving you access to AI-powered Business Process Automation (BPA), Intelligent Documentation Automation (IDP), Decision Engine and API Integration.
Request a Demo
The #1 Enterprise Digital Process
Automation Platform



Frequently Asked Questions
What is IDP (Intelligent Document Processing)?
What are the core benefits of your IDP solution?
How big of an impact can it have?
What type of documents can be processed?
How does your solution compare to competitors?
How are DMS and IDP available in one product? What are the benefits of having two solutions in one?
If a customer wants to adopt our DMS and migrate their data from another solution, what’s the general procedure?
Would I need a separate DMS? What about any other technology?
What if I already have a DMS that I'm happy with?
Is it cloud-based?
Do we have to integrate it with ProcessMaker BPA? Can it run separately?
What is the minimal number of scans required to justify an investment?
What is the difference between AI, Machine Learning, Natural Language Processing, and other solutions? Which do you utilize?
Will IDP reduce costs?
What are the basic technical requirements for ProcessMaker IDP to be deployed?
What are the security features?
What types of technologies are embedded in IDP solutions?
Do we need special equipment to use IDP?
How can you integrate IDP into your environment?
Do you need help to maintain an IDP system?
Learn more about business process automation (BPA)



Discover how leading organizations utilize ProcessMaker to streamline their operations through process automation.